欢迎关注微信公众号「Swift 花园」
要做一个 watch app,逻辑上,你会先想到从主 UI 开始。毕竟,notfication 和 complication 是可选的。人们说到 app ,通常指的就是主 UI 。
但是,如果要做一个在表盘用于浏览空气质量指数的 watch app ,你会先想到 complication 。 watchOS 设计的三大准则之一是 glanceable ,意味着用户能在扫一眼手表,以尽快的方式看到想要的信息,理想的时间最多几秒钟。 complication 可以让看到这些信息,比从 app 启动栏访问主 UI 快得多。
不同于 iOS ,watchOS 的应用并不要求主 UI 一定得是最常用的使用方式 —— 如果用例使得通知和 complication 更合理的话。主 UI 可以充当用户想要查看更具体信息或者特定的动作时的 “回退” 方案。
那么,为什么我们不跳过 view controller ,直接尝试构建一个 complication 呢?
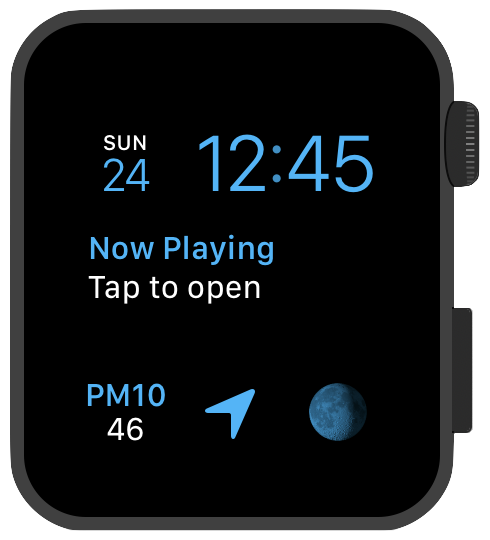
以下是 Kuba 构建的一个简单的 MVP 版本的 watch app ,只有一个 complication (支持 1~2 种变体)。这个 app 没有 UI ,主试图只有一个黑盒子,一行 WKInterface* 对象相关的代码都没有。
这个没有 UI 的 watch app 的用途是获取空气质量的信息(PM10,PM2.5,$ NO_2 $ 等),每个小时更新一次,但足够用了。
下面先了解一些基础知识。
Complication 时间线 管理 complications 的 API 单独从 WatchKit 分离出来,位于 ClockKit 中,以 CLK 前缀标识。
有一些 complication 在你抬腕时就是可见的。当手表的屏幕亮起,你希望立即看到渲染的 complication widget ,它显示的数据当下就必须是最新的 —— 用户很可能只看了它一秒钟不到,因此没有时间在这个时候启动网络请求。
Apple 也不可能采用 7 天 24 小时的方式让应用在后台运行扩展 —— 电池撑不住。
所以工作方式实际上是这样的:你的应用指定一个 complication data source (CLKComplicationDataSource) ,然后每当它接收到新的数据时 (无论运行在前台或者后台),它告诉 complication server (CLKComplicationServer) 通过数据源刷新数据。数据源返回一个 timeline 数据 (一个 CLKComplicationTimelineEntry 的对象) —— timeline 告诉 watchOS complication 在给定时间点到下一个时间点之前应该显示什么数字、文本、图标或者它们的组合。系统缓存这份数据。并且在正确的时间点自动更新显示的内容 —— 你的 app 只有在需要返回 timeline 时才会被唤起,但实际上也可以做到不需要唤起。你可以预先准备一整天的内容,只要你的数据足够提前。
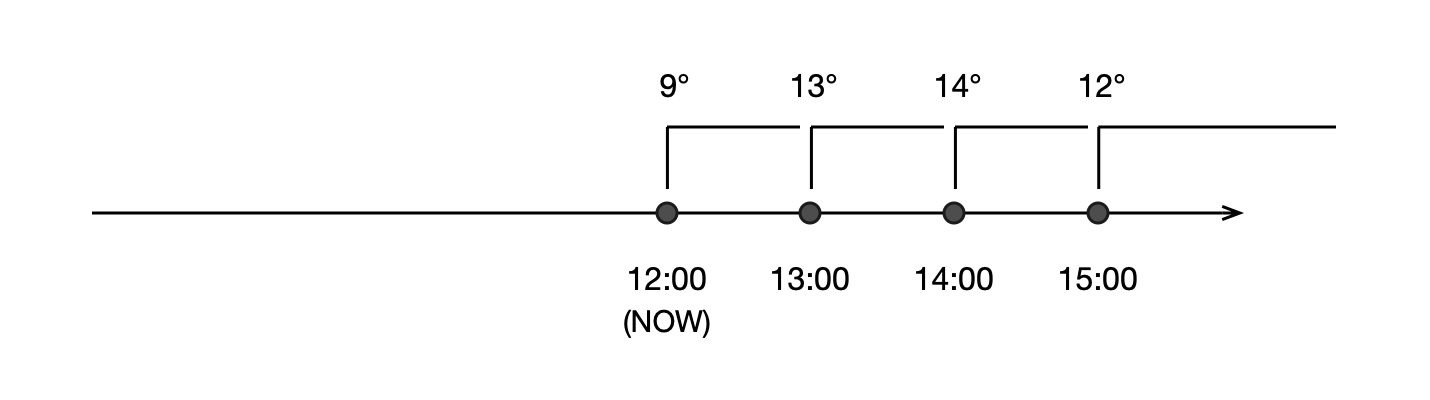
下图是一个经典的天气 app 的例子,点标记 timeline 实体,上面的线显示每个实体被展示的时长。
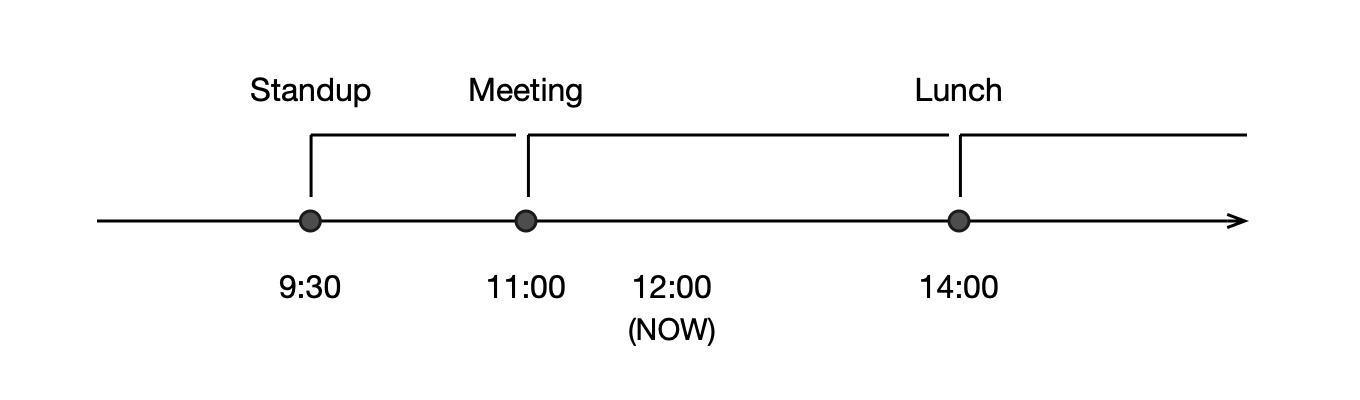
而这个是日历 app 的 complication :
取决于 app 类型,你需要的数据可能是未来的,过去的,两者都有,或者只需要当前状态。
在 Kuba 的案例中,他用的是过去的数据 —— 因为 PM10 这种数据不可能精确预测,它受到很多因素影响,某些是人为的 (比如烧煤取暖这类日常活动)
Time Travel Timeline 的设计还用到 watchOS 的另外一个特性,叫做 “Time Travel” ,它使得你可以在表盘上向前或者向后滚动时间,并更新 complication —— 这使得你可以看到诸如一场比赛中比分变化的过程,或者一只股票在一天中股价变化的过程。
watchOS 5 中这个特性被完全移除了,这意味着现在没办法看过去时间点的数据了。所以在实践中,实现处理过去数据这部分的 complication API 没有意义。
未来的数据仍然有价值 —— 虽然没有办法直接滚动操作了,但是 time travel 还可以工作,只不过是单方向固定节奏了。
有趣的是,这部分无用的 API 尚未被废弃,这意味着未来有回归的可能。
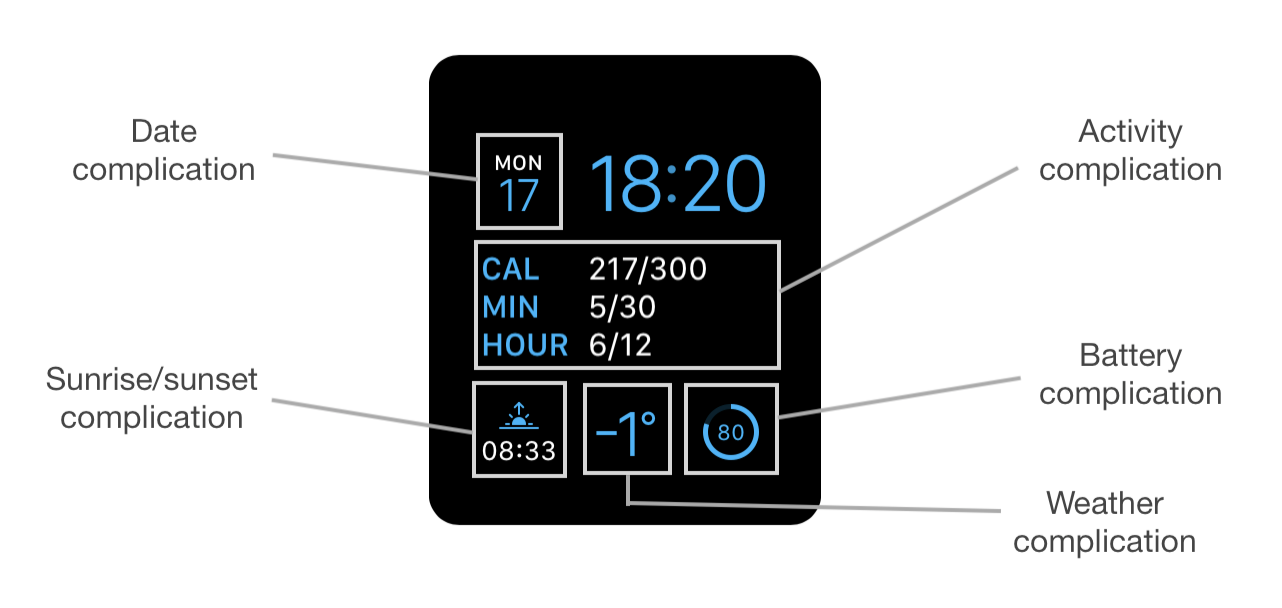
Comlication 家族 在 watchOS 5 中你可以选择多达 26 种样式的表盘。不同的表盘可以适应不同数量和形状的 complications 。这些形状或者 complication 空间的变体被称为 complication famlilies ,目前有 10-11 种 families 可用:
Modular Small, 用于所有的经典模块化表盘,也可用于 Siri 表盘的角落
Modular Large, 只能用在模块化表盘中间唯一的位置
Circular Small, 用于一些不同的表盘 (e.g. Activity)
Utilitarian Small (有 “flat” 变体) 和 Utilitarian Large, 用于占据表盘一半以上空间,展示一条水平的内容 (它有一个模式,容易跟 Circular Small 混淆)
Extra Large, 只用在 X-Large 表盘上
Graphic Corner, Graphic Circular, Graphic Bezel 和 Graphic Rectangular, 只用在 Apple Watch 4 系列的 Infograph 表盘
你可以支持其中任意多你想要的家族子集,当然,理想情况下一个好的 app 是支持所有这些家族,因为不同的人偏好不同的表盘。
项目中为了让事情简单一些,我们只添加了对 Modular Small 和 Circular Small 的支持(覆盖了 11 中表盘,如果没算错的话)。
内容模板 由于资源的限制,你无法在 complication 空间随意绘制东西,你只能使用预定义的模板。模板限定了它们可以包含的内容类型和排布方式。你唯一的选择是选择一种模块,适配给定的空间,放入文本,图标或者值。
举个例子, Circular Small 家族有 6 种可用的模块:
.ringImage, 中间一个图标,然后一个围绕它的环,其他环的哪些部分被填充可以由你指定
大部分模块都只有极其有限的空间用于展示内容,有的时候你需要绞尽脑汁想如何利用给定的空间。如果实在想不出来,那么放弃对特定 complication 家族的支持也是可以的。
你的 app 会一些不同的状态 —— 例如,有或者没有数据,空或者非空数据列表,有或者没有进行中的活动等等。所以根据状态来选用不同的模块是可以的(比如,某些状态用数字,某些状态用图标)。每当你构建 timeline 时,你可以创建全新的模板对象并且用它们填充内容,所以只要你开心,甚至可以每次采用随机模板。
文本和图像 providers 为了渲染不同类型内容的灵活性, timeline 数据并非简单地以 String 或者 UIImage 对象的形式返回,而是借助某种可用的 provide 对象封装。这些 provider 使得你的内容可以更加动态,根据时间和上下文变化。
对于文本,最简单的选项是 CLKSimpleTextProvider ,你可以指定单一的字符串以及一个可选的简短版本,如果空间无法容纳完整字符串,则选取简短版本。
作为替代方案,有几种时间相关内容的 provider 可供选择:
CLKDateTextProvider 输出日期 (日 / 月)CLKTimeTextProvider 输出特定时间 (小时 / 分钟)CLKTimeIntervalTextProvider 输出时间范围 (from-to)CLKRelativeDateTextProvider 输出自某个时间开始或者到某个时间结束 (例如 “2 小时后”)
上面最后一种会随着时间的流逝自动更新,你只需要配置一次目标时间戳,而不用每小时或者更频繁地手动更新,例如 “5 小时后”,“4 小时后” 等等。
对于图像,你通常用 CLKImageProvider 。它让你指定一个模板图像(被渲染为单色)和一个颜色。多少情况下,这个颜色会被忽略,因为大部分表盘都是以用户选定的单一颜色渲染所有的 complications 。有一个叫 CLKFullColorImageProvider 的模块可以以全彩的方式渲染图像,但只在新的 Infograph 表盘才用到。
模拟 Infograph 表盘上的 complications 还用到一些 CLKGaugeProvider —— 它们是用于配置新表盘角落里的彩色弧线。
出发!
首先,创建工程,使用模板 “watchOS > iOS App with WatchKit App” ,确保 “Include Complication” checkbox 勾选。
工程将包含 3 个 targets:
SmogWatch, 它是 iOS app (这个案例里我们基本不碰这部分)
SmogWatch WatchKit App, UI 部分,只包含了 storyboard, (包括主 UI 和可能的 notification 场景) 以及 asset catalog 。
SmogWatch WatchKit Extension, 包含所有的 WatchKit 代码
在导航栏中选择 “SmogWatch WatchKit App” 目标运行。
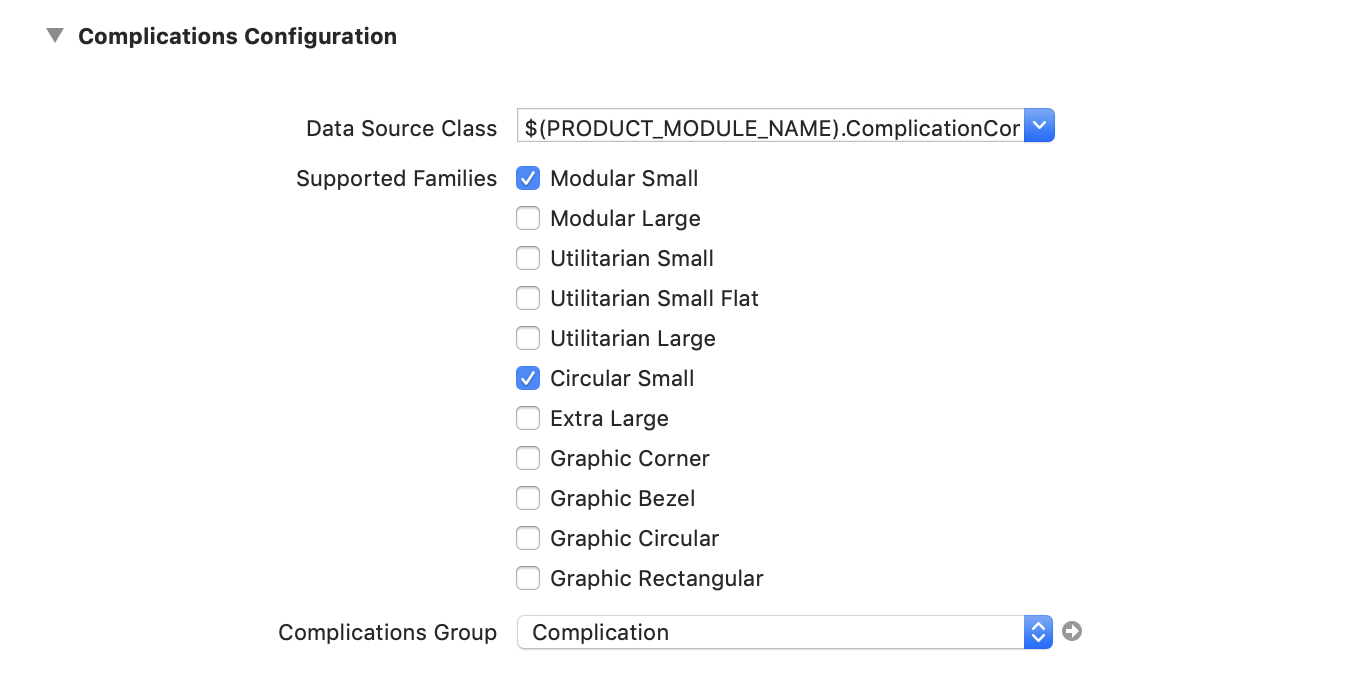
设计模板 如上文所提,为了让事情更简单,我们只是实现 Modular Small 和 Circular Small complication 家族。不过默认情况下所有的 complication 家族都是启用的,所以你需要禁用掉其他的。
打开 “SmogWatch WatchKit Extension” target 的配置页,在 “General” tab 你会看见一个可以触发 complication 家族的列表:
接下来,要确定每个 complication 家族要采用什么模板。在 CloudKit 文档 中,找到 Modular Small 家族。在它的页面上,你会看到 7 种可用的模板类以及它们的效果截屏。
在我们的案例中,我们主要显示小数字,所以下面几种选项可能是合理的:
显示数字,例如 “75” - 可读性没问题,但是第一眼看数字代表什么不明显
以一个圆来显示数字 - 弧应该怎么算,没有上限怎么办?
以上面是图标,下面是数字的方式显示
以两行文本显示
最后,我选择了像下面这样的样式:
这个方案解决了展示 app 是什么的类型,同时也支持解释不同类型参数的问题,缺陷是使得字体更小了,尤其是 3 个数字的情况。尽管仍然可读,但是 Circular Small 版本肯定效果不好。因此,对于 Circular Small ,选项相似,也选择了两行文本的版本。
上面这个可读性差很多,但是 Circular Small 是非常通用的 complication 家族,因此基本上对所有使用者都是一个挑战。Apple 自己的 complications ,比如世界时钟,日出、日落,看起来也没有好多少。我们这里可以放弃 “PM” ,但这样一来又搞不清 app 是干什么用的,所以折中,把 “PM10” 缩短为 “PM” 。有可能上面用图标效果会更好,读者可以尝试一下。
实现 Complication 数据源 现在,打开样板代码 ComplicationController 类,这里已经数据源协议所有要求的方法了,一些是空实现,但其中大多数我们并不需要。
注意,所有的方法都是通过一个 handler callback 返回数据的。这使得你可以通过某些异步的方式加载要求的数据 —— 理论上,你是可以按需在用到时再加载这些数据,但实际上我们绝不应该这么做。
所有的方法都传入一个 CLKComplication 对象作为参数,它让你知道系统现在正为哪一种 complication 向你询问数据,这个对象只有一个字段叫 family ,这意味着在一个 Modular 表盘上,你无法区分同族的两个 complication 实例,但是不同族的可以。
因此,这个信息绝对是必须的 —— 不仅因为不同家族外观看起来不一样,也是为了让编译器匹配你返回的模板类型。
CLKComplicationDataSource 协议里只有 getSupportedTimeTravelDirections 和 getCurrentTimelineEntry 两个方法是必须得实现的,但我们会先从一个可选的方法开始讲。
样例模板 我们要看的第一个方法是 getLocalizableSampleTemplate ,在文件的底部 —— 你有可能会需要在把 complication 添加到表盘之前先实现这个方法。
这个方法让你返回一个 complication 的 “样例” 外观,它是当用户在表盘配置视图中设置 complication 时用到的。这里应当展示一些随机数据,表现你的 complication 一般情况下的外观,就像你在应用的网站或者应用商店上放的截图那样的东西。
在这个方法中,我们需要返回一个 CLKComplicationTemplate 对象 —— 在实际的 timeline 中,我们也会返回一样的东西。不过这里不指定时间戳。对于两种 complication 家族,我们都用标准的 CLKSimpleTextProvider 来封装返回的文本。 在样例模板里,我们用 “50” 来代替真实值。
下面是代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func getLocalizableSampleTemplate ( for complication: CLKComplication, withHandler handler: @escaping (CLKComplicationTemplate?) Void ){ switch complication.family { case .modularSmall: let template = CLKComplicationTemplateModularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM10" ) template.line2TextProvider = CLKSimpleTextProvider (text: "50" ) handler (template) case .circularSmall: let template = CLKComplicationTemplateCircularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM" ) template.line2TextProvider = CLKSimpleTextProvider (text: "50" ) handler (template) default : preconditionFailure ("Complication family not supported" ) } }
记得总是返回匹配给定 complication 家族的模板。不幸的是,好像没有可以在编译期检查这个过程的机制。
这里,我们为两种家族都选用了 “stack text” 模板,因此都有 line1TextProvider 和 line2TextProvider 属性。如果你选择另外的配置的话,可能的属性有 imageProvider , headerTextProvider , ringStyle 等等。
如果系统向我们请求其他我们不支持的 complication 类别的话,我们在默认 case 抛出断言 —— 但这不应该发生,因为我们已经禁用所有其他类型的 complication 。用 preconditionFailure 触发崩溃是为了确保自己不忘掉一些东西,最终版本其实应该返回 nil 更安全。
之所以先说这部分,是因为无论你在这个模板返回了什么,它都会被系统缓存。如果你改变了代码再次运行,你不会看到任何效果 —— 你需要从模拟器中删除 app ,重新安装以便更新版本。
现在,当你运行 app ,你可以编辑表盘(通过用力按压 MacBook 的 touchpad ,或者在菜单 Hardware > Touch Pressure),选择一个 complication 空间,并且选择你的 complication :
注意,默认你的 app 名是 app target 的完整名,这会有点长。为了把它改成更可读的,打开 WatchKit app target 的 Info.plist (注意,是 app 而不是 extension 的) 然后把 “Bundle display name” 改成 “SmogWatch” 。
当你退出编辑模式并返回表盘,你会看到你放置 complication 的地方有一个空白的空间 —— 别急,我们接下来就着手处理这块。
getSupportedTimeTravelDirections 这个方法告知系统你的 app 在过去、未来、两个方向或者只有当前时刻拥有数据。因为之前提到过去的数据已经不再使用了,所以只有返回 .forward 或者空列表是有意义的。由于我们并不需要预测未来的空气质量,所以我们只需要返回一个空的列表:
1 2 3 4 5 6 func getSupportedTimeTravelDirections ( for complication: CLKComplication, withHandler handler: @escaping (CLKComplicationTimeTravelDirections) Void ){ handler ([]) }
这里返回的东西决定了系统是否会调用 getTimelineStartDate , getTimelineEndDate , getTimelineEntries (for:before:limit:withHandler:) 和 getTimelineEntries (for:after:limit:withHandler:) 这些方法,以询问你 timeline 在两个方向上延展的长度,时点。如果我们返回 [] ,那么系统只会询问当前时点。
不过这些方法都是可选的,所以如果你都不实现它们, watchOS 会假定当前时点没有什么有趣的东西。
getCurrentTimelineEntry 这是整个协议核心的代码,它是我们返回最新数据点的地方。
timeline 数据是以一个或者多个 CLKComplicationTimelineEntry 对象返回的。一个 timeline 实体其实就是一个时间戳加上一个或者多个指派的数据 provider ,里面填充着你需要的数据。实体借由时间戳验证。
目前我们还没有实际拥有数据,不过别担心 —— 我们可以先返回一个静态数值,比如 75 ,就像样例模板中的做法一样。我们使用当前时间作为时间戳,因为根据前面方法返回的设定,我们不会被询问任何在当前时点之前的时段数据。
下面是 getCurrentTimelineEntry 的初始版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func getCurrentTimelineEntry ( for complication: CLKComplication, withHandler handler: @escaping (CLKComplicationTimelineEntry?) Void ){ let entry: CLKComplicationTimelineEntry switch complication.family { case .modularSmall: let template = CLKComplicationTemplateModularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM10" ) template.line2TextProvider = CLKSimpleTextProvider (text: "75" ) entry = CLKComplicationTimelineEntry (date: Date (), complicationTemplate: template) case .circularSmall: let template = CLKComplicationTemplateCircularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM" ) template.line2TextProvider = CLKSimpleTextProvider (text: "75" ) entry = CLKComplicationTimelineEntry (date: Date (), complicationTemplate: template) default : preconditionFailure ("Complication family not supported" ) } handler (entry) }
当你添加了以上两个方法,编译运行你的 app 到模拟器。你应该会在 complication 里看到我们配置的模板和数值:
如果你还是没有看到效果,那可能是因为系统缓存了之前编译版本的状态。为了强制加载 complication ,你可以进入编辑模式,切到不同的 complication ,退出编辑模式。 然后再进入编辑模式,切回你的 complication 。
可选的方法 在数据源协议中还有一些其他的协议,但针对我们的用途,我们只需要用到 getTimelineEntries (for:after:limit:withHandler:) 。这个方法询问我们早前传入的 timeline 时点之后的时点。当我们写的 app 需要提前了解某个时点时,会用到这个方法。例如,天气预报,日历事件,todo list 上预定的任务等。不过,大部分 app 只需要显示当前实体就够了。
我们在这个 app 中使用这个 API 的作用是,我们很可能需要在时点过去之后将未来版本的数据标记为过时。如果你查看的是 6 个小时前的空气质量,它很可能是没什么价值的,因为当前的空气很有可能已经发生显著的变化。在 Krakow ,这种变化可能发生在 2 个小时内。例如,起风或者风停了。所以,我们可能在几小时后自动隐藏掉当前数值,借助添加一个几小时后的 “重置” 数据来实现。如果我们成功地在每个小时更新了数据,那么备选的第二个时点的数据永远不会被展示,但是如果有些东西出错了,那么当时间变化足够长,会在时点到来时借助这个 API 来更新数据。
我认为 watchOS 之前应该也是这么干的,至少在 Time Travel 功能里是这么做的 —— 文档里也提到了。不过这本该是 getTimelineStartDate 和 getTimelineEndDate 方法存在的意义 —— 但是由于这两个 API 不起作用 (Time Travel),所以实现它们也没意义。
从网络上获取真实数据 对于第一个版本,我们用使用 Małopolska 地区空气监控系统的公共数据 (仅限波兰) 。
前端通过一个挺复杂的 POST 请求,发送到 URL http://monitoring.krakow.pios.gov.pl/dane-pomiarowe/pobierz ,然后解析返回的 Json 数据。
这个主题并不是跟 watchOS 特定相关,它是特定于 web API —— 所以这里不详细描述,下面是拉取和解析数据的完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 import Foundation private let DataURL = "http://monitoring.krakow.pios.gov.pl/dane-pomiarowe/pobierz" class KrakowPiosDataLoader let dateFormatter: DateFormatter = { let d = DateFormatter () d.locale = Locale (identifier: "en_US_POSIX" ) d.dateFormat = "dd.MM.yyyy" d.timeZone = TimeZone (identifier: "Europe/Warsaw" )! return d }() let dataStore = DataStore () let session: URLSession = { let config = URLSessionConfiguration .ephemeral config.timeoutIntervalForResource = 10.0 return URLSession (configuration: config) }() func queryString () String { let query: [String : Any ] = [ "measType" : "Auto" , "viewType" : "Parameter" , "dateRange" : "Day" , "date" : dateFormatter.string (from: Date ()), "viewTypeEntityId" : "pm10" , "channels" : [148 ] ] let jsonData = try ! JSONSerialization .data (withJSONObject: query, options: []) let json = String (data: jsonData, encoding: .utf8)! return "query=\(json)" } func fetchData (_ completion: @escaping (Bool) var request = URLRequest (url: URL (string: DataURL )!) request.httpBody = queryString ().data (using: .utf8)! request.httpMethod = "POST" NSLog ("KrakowPiosDataLoader: sending request to %@ with %@ ..." , DataURL , queryString ()) let task = session.dataTask (with: request) { (data, response, error) in var success = false if let error = error { NSLog ("KrakowPiosDataLoader: received error: %@" , "\(error)" ) } else { NSLog ("KrakowPiosDataLoader: received response: %@" , data != nil ? "\(data!.count) bytes" : "(nil)" ) } if let data = data { if let obj = try ? JSONSerialization .jsonObject (with: data, options: []) { if let json = obj as ? [String : Any ] { if let data = json ["data" ] as ? [String : Any ] { if let series = data ["series" ] as ? [[String : Any ]] { if let first = series.first { if let points = first ["data" ] as ? [[String ]] { if let point = points.last { let date = Date ( timeIntervalSince1970: Double (point [0 ])! ) let value = Double (point [1 ])! self .dataStore.currentLevel = value self .dataStore.lastMeasurementDate = date NSLog ("KrakowPiosDataLoader: saving data: " + "%.0f at %@" , value, "\(date)" ) success = true } } } } } } } } if !success { NSLog ("KrakowPiosDataLoader: no data found" ) } completion (success) } task.resume () } }
不要忘记在最后用 resume () 启动任务。
小结:
我们向 API 请求 PM10 的数据,硬编码请求当天和特点地点。
我们只取最后的测量结果 (多数情况下是最近一两个小时的数据)
如果我们拿到数据,存储一个数字,表示 PM10 的浓度,以及测量的时间点
通知调用方我们拿到或者没有拿到数据
上面的代码用了老式的 Json 解析方法,因为我认为这样比较容易理解。
我用老式的 NSLog 而不是 Swift 的 print () ,是因为后者只会显示在 Xcode 的控制台,并不会记录到系统日志,所以在控制台 app 的诊断日志里看到,在某些情况下你需要在 app 没有连接 mac 时跟踪它的行为。
还有,注意我们是在前台请求数据,用最基本的 URL session 。这不是通常我们最理想的应用方案 —— 理想的,所有的请求都应该是在后台 URL sessions 中完成,不过这里只是一个最小可用原型,先保持这样吧。
不过我们通过把超时时间设置为每次请求不超过 10 秒钟来限制了 URL session。 这里 timeoutIntervalForResource 的用法,而不是 timeoutIntervalForRequest 或者 timeoutInterval 很重要,因为自上一次接收到数据包后,后面两个只会在空闲时间工作,而我们希望控制总的请求时间。之所以要控制总时间,是因为看起来这里边有一个针对后台任务的硬性限制,并且没有在文档中提到:如果一个 app 超出了 15 秒的后台运行时间,它会被立即杀死,崩溃报告如下:
Termination Reason: CAROUSEL, Background App Refresh watchdog transgression. Exhausted wall time allowance of 15.00 seconds. Termination Description: SPRINGBOARD, CSLHandleBackgroundRefreshAction watchdog transgression: eu.mackuba.SmogWatch.watchkitapp.watchkitextension exhausted real (wall clock) time allowance of 15.00 seconds (…)
为了便于你了解最后一次检测的时间点,我们把 lastMeasurementDate 时间戳存进了 DataStore ,这是一个我们可以用来实现之前提到的 “过时数据 特性的潜在结构。
那么这个 DataStore 究竟是什么?其实只是 UserDefaults :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private let CurrentLevelKey = "CurrentLevel" private let LastMeasurementDate = "LastMeasurementDate" class DataStore let defaults = UserDefaults .standard var currentLevel: Double? { get { return defaults.object (forKey: CurrentLevelKey ) as ? Double } set { defaults.set (newValue, forKey: CurrentLevelKey ) } } var lastMeasurementDate: Date? { get { return defaults.object (forKey: LastMeasurementDate ) as ? Date } set { defaults.set (newValue, forKey: LastMeasurementDate )} } }
最后,我们需要添加一个例外域名到 WatchKit Extension target 的 App Transport Security 设置中,因为这个域名不支持 Https 。
1 2 3 4 5 6 7 8 9 10 11 <key > NSAppTransportSecurity</key > <dict > <key > NSExceptionDomains</key > <dict > <key > monitoring.krakow.pios.gov.pl</key > <dict > <key > NSExceptionAllowsInsecureHTTPLoads</key > <true /> </dict > </dict > </dict >
显示真实数据 为了实际加载数据,我们需要在某个地方调用这个类的方法。我们来看一看 ExtensionDelegate 这个类,它实现了 WKExtensionDelegate —— 基本上就是一个 WatchKit 版本的 UIApplicationDelegate 。就像所有的 app 代理, WKExtensionDelegate 有许多生命周期方法,这些方法会被系统在各种时刻调用: applicationWillEnterForeground , applicationDidBecomeActive , applicationWillResignActive 和 applicationDidEnterBackground 等等。
这里头我们目前唯一会用到的是 applicationDidFinishLaunching 。这个方法会在 app 进程启动时被调用 —— 无论是通过 app launcher 或者通过 Xcode ,又或者从后台启动。只要是 app 需要被唤起,并且之前已经被系统清理掉的时候,这个周期都会运行 (通常在晚上,被系统杀死的情况经常发生) 。
无论何时, app 启动或者在后台重启,我们都希望借助这个机会立即拉取最新的数据,如果我们得到响应,重新加载所有活动的 complication (活动的 complication 指那些在当前选择的表盘上显示的 complication)。
所以我们将这样做:
1 2 3 4 5 6 7 8 9 func applicationDidFinishLaunching () NSLog ("ExtensionDelegate: applicationDidFinishLaunching ()" ) KrakowPiosDataLoader ().fetchData { success in if success { self .reloadActiveComplications () } } }
为了拉取数据,我们调用了 KrakowPiosDataLoader 类,然后在有任何新数据的情况下重载加载 complications ,否则的话就不必了。在 watchOS 上,不要浪费时间做无用功,这是一条通用的准则。
为了重新加载 complications ,我们得拿到活动 complication 的列表,这是借由全局共享的 CLKComplicationServer 实例来获得的,并且也通过它的 reloadTimeline (for:) 方法来重新加载那些活动的 complication 。如果打算在已经存在的 timeline 实体后追加新的 timeline 实体,我们也可以用另一个相似方法 extendTimeline (for:) ,两者的区别是前者我们希望立刻用新数据替换掉之前的数据。
1 2 3 4 5 6 7 func reloadActiveComplications () let server = CLKComplicationServer .sharedInstance () for complication in server.activeComplications ?? [] { server.reloadTimeline (for : complication) } }
上面的代码会触发一轮对你的 CLKComplicationDataSource 的调用 —— 有的时候是一会之后,不过通常几乎都是立刻发生。现在我们有了真实数据,我们可以回到之前写的 getCurrentTimelineEntry 方法,然后把占位的代码替换成实际的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 func getCurrentTimelineEntry ( for complication: CLKComplication, withHandler handler: @escaping (CLKComplicationTimelineEntry?) Void ){ let store = DataStore () let entry: CLKComplicationTimelineEntry let date: Date let valueLabel: String if let lastMeasurement = store.lastMeasurementDate, let level = store.currentLevel { valueLabel = String (Int (level.rounded ())) date = lastMeasurement } else { valueLabel = "--" date = Date () } switch complication.family { case .modularSmall: let template = CLKComplicationTemplateModularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM10" ) template.line2TextProvider = CLKSimpleTextProvider (text: valueLabel) entry = CLKComplicationTimelineEntry (date: date, complicationTemplate: template) case .circularSmall: let template = CLKComplicationTemplateCircularSmallStackText () template.line1TextProvider = CLKSimpleTextProvider (text: "PM" ) template.line2TextProvider = CLKSimpleTextProvider (text: valueLabel) entry = CLKComplicationTimelineEntry (date: date, complicationTemplate: template) default : preconditionFailure ("Complication family not supported" ) } handler (entry) }
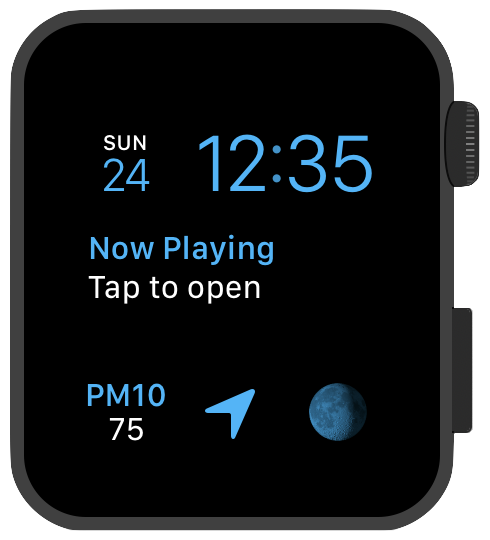
现在,当我们运行 app 时,点击 home 按钮返回表盘时,我们会看到一个刚刚借助 API 加载的真实数据:
1 2 3 4 5 6 ExtensionDelegate: applicationDidFinishLaunching () KrakowPiosDataLoader: sending request to http://monitoring.krakow.pios.gov.pl/dane-pomiarowe/pobierz with query={"viewTypeEntityId": "pm10", "measType": "Auto", "viewType": "Parameter", "dateRange": "Day", "date": "24.02.2019", "channels": [148]} ... KrakowPiosDataLoader: received response: 1553 bytes KrakowPiosDataLoader: saving data: 46.4462 at 2019-02-24 10:00:00 +0000
安排更新 最后的拼图是确保我们可以按照有规律的间隔加载新的数据并重新加载 complication 。有一些场景你可以更新 complications :
当你的 app 处于前台时,你总是可以做这件事 —— 但你无法依赖它定期发生。
当你接受到一些静默的推送通知时,尤其是专门为这种用途设计的 (借助 PushKit framework ,采用 PKPushTypeComplication 类型) —— 当你的数据以不规则间隔更新时,这种机制会有用 —— 当外部发生一些事件时。
当 iPhone app 以某种方式接收到新的数据并把它传输给 watch 时
通过计划定期的后台刷新 —— 当你希望拉取数据而不是被动等推送时,这种方式更好。
注意,不管你采用哪种策略,对于我们刷新数据的频率以及完成刷新的用时,有许多限制。 (比如,每天不超过 50 个推送通知) —— 如果你用尽了所有的时间或者每天可用的推送数量,你将无法再在后台运行,有可能要等到第二天。对于这点约束,看起来没有什么特别好的方案可以绕过,你也不应该尝试去寻找这类方案。
既然我们知道城市监测站每小时发送一次新的测量数据,我们会使用计划好的后台刷新来更新我们的 complication ,并且会在 ExtensionDelegate 中完成。
为了确保我们的 app ,我们需要实现一样我称为 “后台刷新循环” 的东西:当 app 启动或者重启时,我们安排一次后台刷新,然后当 app 被这个后台刷新唤起时,我们做的第一件事就是安排下一次后台刷新,以确保若干时间后总有新的刷新被计划。
我们会在所有其他事情之前开始做刷新计划,因为我们无法知道在我们的 app 被挂起或者杀死之前还有多少可用的时间。否则,如果在我们设置下一次刷新之前 app 就被挂起,那么 app 就相当于没设闹钟就睡过去了,那么它将会睡过头。 😉
现在,让我们再看一下 applicationDidFinishLaunching 方法,我们需要在 web 请求发送之前增加一个新的方法调用 scheduleNextReload () :
1 2 3 4 5 6 7 8 9 10 11 func applicationDidFinishLaunching () NSLog ("ExtensionDelegate: applicationDidFinishLaunching ()" ) scheduleNextReload () KrakowPiosDataLoader ().fetchData { success in if success { self .reloadActiveComplications () } } }
计算下一次刷新时间 在计划下一次刷新前,我们首先需要定出下一次刷新的时机。
为了优化后台刷新的耗时,尽可能利用好珍贵的后台时间,思考清楚我们的数据究竟需要在何时和以何种频率改变。一个很好的例子是 —— 证券交易只发生在工作时间,不在工作时间内,股票价格不会变化,所以在夜间重载不会改变的数据是没有意义的。
我对获取数据的 API 做了一些测试,新的数据几乎总是 1 个整小时的 0 到 10 分钟内添加。所以我决定每小时请求一次刷新,总是在每小时的 15 分做这件事 (10:15 , 然后 11:15, 然后 12:15 ,以此类推)。为了实现这种方式,我们需要一个辅助方法来让我们基于当前时间找到最接近 xx:15 的时间 —— 幸运的是,利用 NSCalendar API 很容易做到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func nextReloadTime (after date: Date) Date { let calendar = Calendar (identifier: .gregorian) let targetMinutes = DateComponents (minute: 15 ) var nextReloadTime = calendar.nextDate ( after: date, matching: targetMinutes, matchingPolicy: .nextTime )! if nextReloadTime.timeIntervalSince (date) < 5 * 60 { nextReloadTime.addTimeInterval (3600 ) } return nextReloadTime }
计划后台刷新 最后,为了在计算好的未来时点请求更新,我们需要在 WKExtension (等价于 UIApplication) 上调用 scheduleBackgroundRefresh :
1 2 3 4 5 6 7 8 9 10 11 func scheduleNextReload () let targetDate = nextReloadTime (after: Date ()) NSLog ("ExtensionDelegate: scheduling next update at %@" , "\(targetDate)" ) WKExtension .shared ().scheduleBackgroundRefresh ( withPreferredDate: targetDate, userInfo: nil , scheduledCompletion: { _ in } ) }
你传入的日期是你希望你的 app 被唤起的时间。当然,系统会把它看做一种提示 —— 你的 app 实际被唤起的时间还可能取决于各种因素(我猜测这其中包含电量,充电状态,网络访问,你请求刷新的频率,你每次刷新的耗时,等等)。所以,不要假定你的 app 总是能在固定的间隔运行。
不过,基于我的测试,在实践中一个拥有一个活动 complication ,每隔一个小时更新的 app ,通常在 10 秒以后的请求时间,在白天的表现比在夜间充电的表现要好很多,或者 app 运行频繁,或者 app 处于 dock 但是没有 complication 时,后台任务被调用的机会更少。不在 dock 也不没有 complication 的 app ,几乎不被调用。
scheduledCompletion 块在文档中被描述为 “A block that is called by the system after the background app refresh task has completed” ,但是实际上它是在下一个刷新任务计划完成时就被立即执行。不过由于它是一个可选的参数,你可以提供一个空的块。至于 userInfo ,它可以传递一些元数据给后台任务的 handler ,但这里我们用不上。
处理后台任务 watchOS 上的后台刷新是通过在各种时刻从后台唤起你的 app ,然后调用代理方法 handle (_ backgroundTasks:) ,传给它一个或者多个取决于上下文的 “后台任务”。这个方法对于你的 app 后台事务至关重要,不管你构建的 app 是什么类型,几乎一定要在这里做些事情。
任务的类型有不少,但你应当做跟当时接收到的任务相关的工作。比如有的任务是处理 URLSession 返回的数据,有的任务是处理 iPhone 返回的数据,有的任务是处理 Siri 快捷方式,但是这里我们要处理的是一种通过之前的 scheduleBackgroundRefresh 发起的任务 —— 这是一种最普通的 WKApplicationRefreshBackgroundTask 。这种任务意味着你的 app 是由于你自己的请求而被唤起的,以便你可以运行一些后台的 URL 请求,更新你的 complication 等等。
当 app 在后台被唤起时,在 handle (_ backgroundTasks:) 方法中,我们做的事情跟启动时的差不多 —— 我们计划下一次刷新,并尝试更新数据。注意,我们只用了 WKApplicationRefreshBackgroundTask ,忽略其他的任务类型。不过,在完成任务后,记得总是调用 setTaskCompletedWithSnapshot () 方法,这很关键,即便对于那些被你忽略掉并且不处理的任务。不过,调用这个方法表明我们的事干完了,在这之后我们的 app 可能会被挂起。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func handle (_ backgroundTasks: Set<WKRefreshBackgroundTask>) for task in backgroundTasks { switch task { case let backgroundTask as WKApplicationRefreshBackgroundTask : NSLog ("ExtensionDelegate: handling WKApplicationRefreshBackgroundTask" ) scheduleNextReload () KrakowPiosDataLoader ().fetchData { success in if success { self .reloadActiveComplications () } NSLog ("ExtensionDelegate: completed WKApplicationRefreshBackgroundTask" ) backgroundTask.setTaskCompletedWithSnapshot (false ) } default : task.setTaskCompletedWithSnapshot (false ) } } }
让 watchOS 模拟器运行 app 后台刷新任务需要一些技巧,即使你已经安排它们在一会之后运行。如果你测试时发现不工作,可以尝试随机切换 app ,主屏和表盘,直到后台刷新任务可以工作。
总结 就这些,我们完成了!🎉 我们得到一个每小时运行的 app ,从 web API 加载新数据,显示到你选择的表盘上,你只要抬腕就能看到它。
依我看来,为了构建一个带 complication 的最小可行的 watch app ,你需要做这些事:
确定你的 app 想要在 complication 上展示的最重要的东西。
确定你的 complication 内容什么时候改变,你的 timeline 存放什么以及存在哪里。
浏览 complication 家族以及对应可用的模板,确定哪些最适合你
实现从 web 或者系统 API 加载数据的代码
实现 complication 数据源要求的方法,以构建 CLKComplicationTimelineEntry 和 CLKComplicationTemplate 对象,以合适的方式展示你的内容。
确保你的 app 定期更新,用计划的后台刷新或者借助推送通知 (分析你的数据变化的模式,以便优化后台时间)
测试,测试,再测试,用任何你能想到的场景和组合 🙂
如果你只是构建一个静态的 complication ,永远不更新,就像 Apple 的 “launcher” 型的 complications , 比如 Breathe , Maps , Reminders 等等。那么,你只需要做这些事:
为所有支持的 complications 挑选一个图标。
实现数据源方法,用 “single icon” 模板返回单一实体的 timeline 。
这种情况下你不需要计划后台刷新以更新 complication ,因为它永远不变。不过,由于 complication 需要链接到真实 app 时,也有大量工作需要做。 😉
工程中的代码可以从这个仓库找到: https://github.com/mackuba/SmogWatch (master 分支最新代码,或者对应这篇文档的 post2 分支的版本)。 它是 WTFPL-licensed ,所以尽管拿去用,你可以分享给我你都做出什么好玩的东西!