欢迎关注微信公众号「Swift 花园」
比例的置信区间
在过去的几周中我认识到新生儿喜欢排便,频繁地排便。恰好我的女儿 Lois 尤其喜欢在特定的情况下排便 —— 在我给她换尿布的时候。我说真的,一旦她决定上厕所 (answer nature’s call) ,一上就是六次。是的,六次,发生在换尿布的过程中。

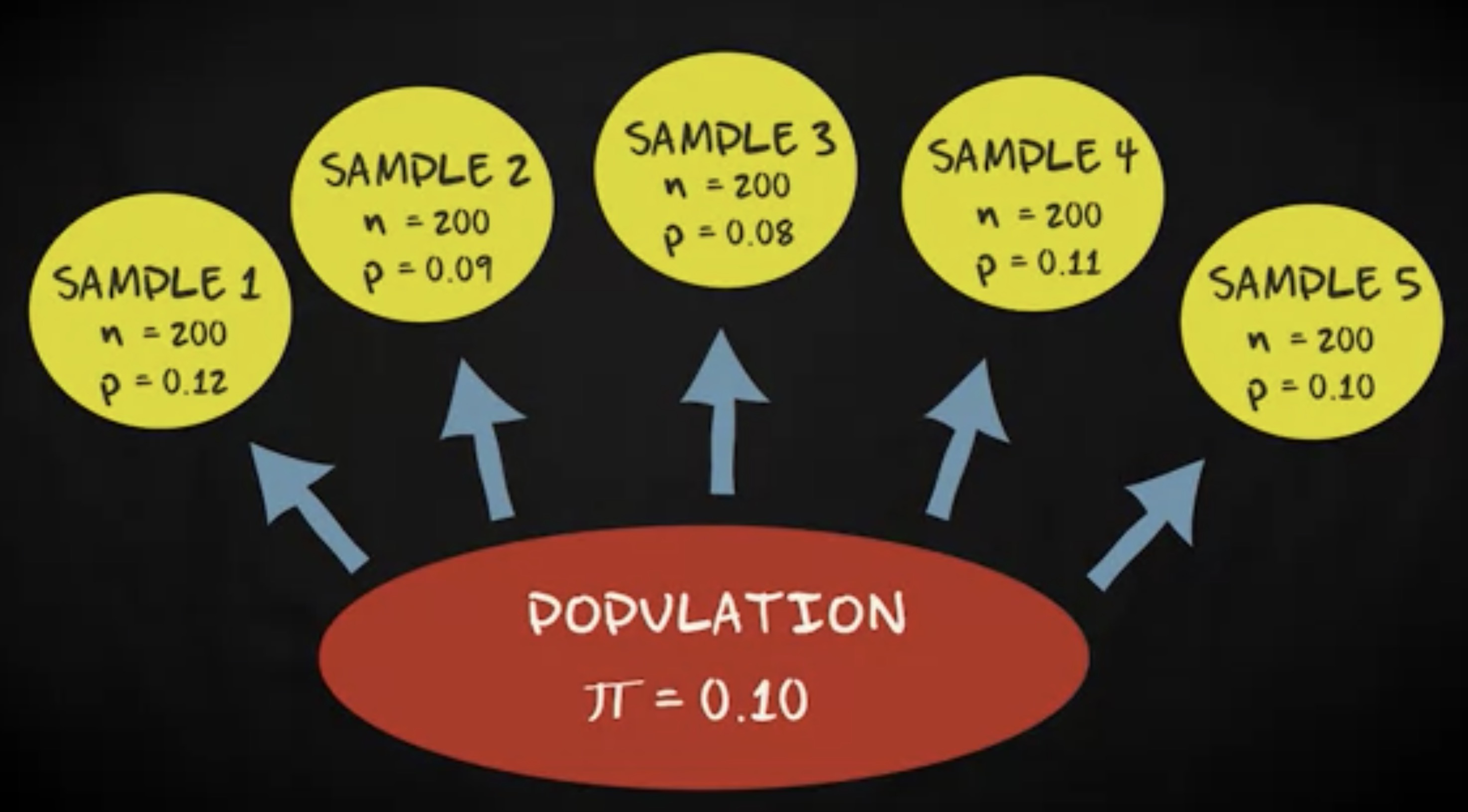
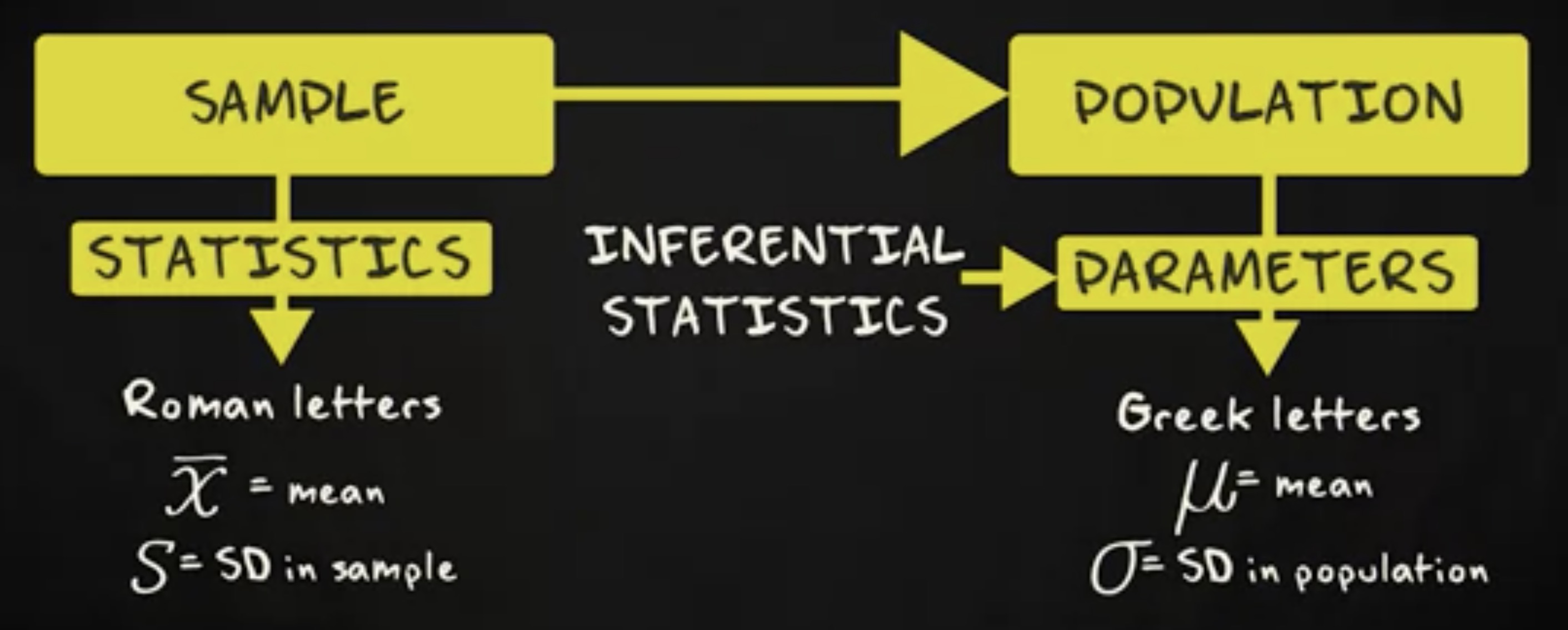
这正常吗?我不确定,但我知道我需要搞清楚。假定我随机问 100 个新生儿的父母,他们的宝宝是否喜欢在换尿布时排便。在这一节教程中,我会告诉你,如何基于这样一个研究,构建一个估计总体比例的置信区间。
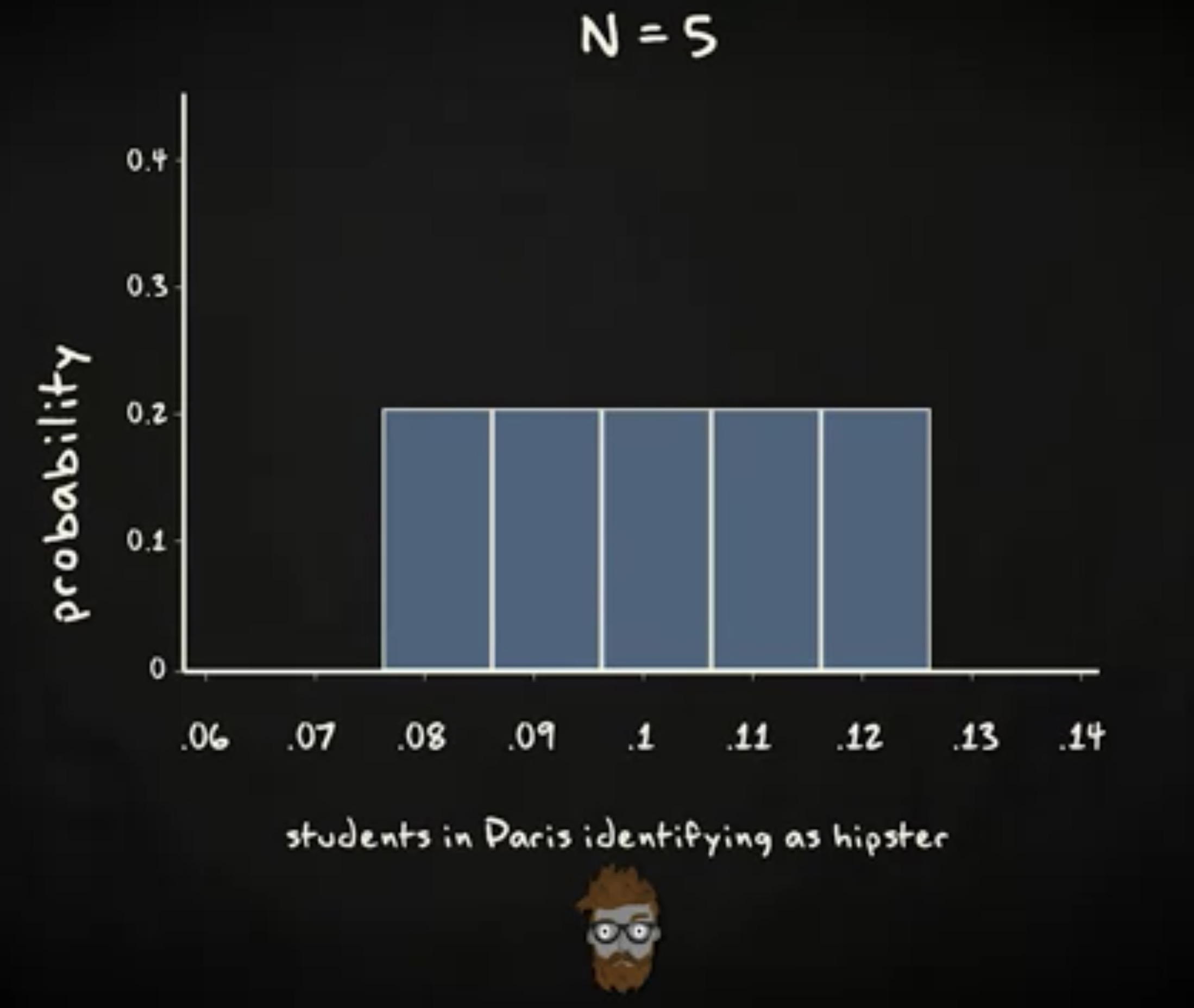
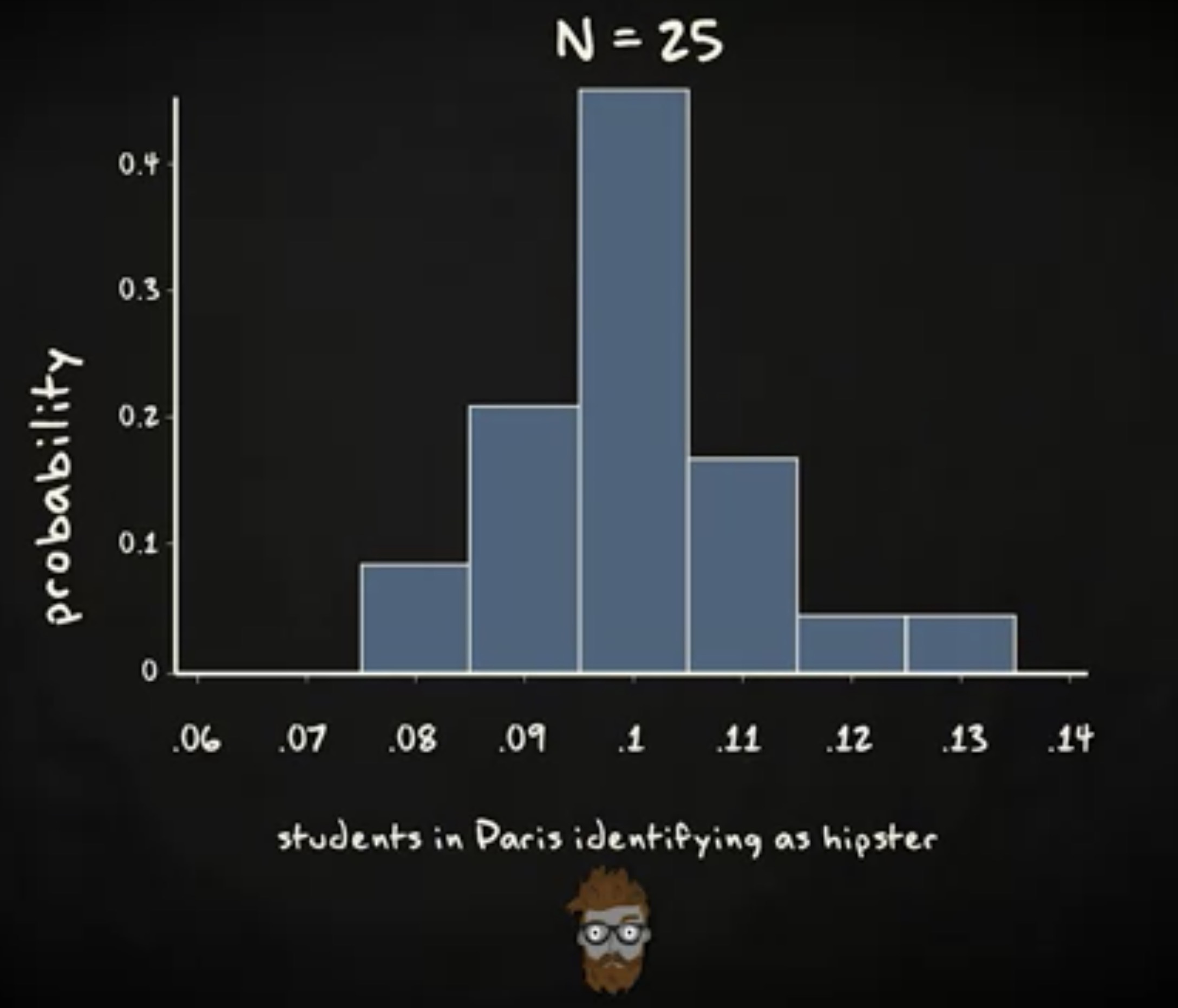
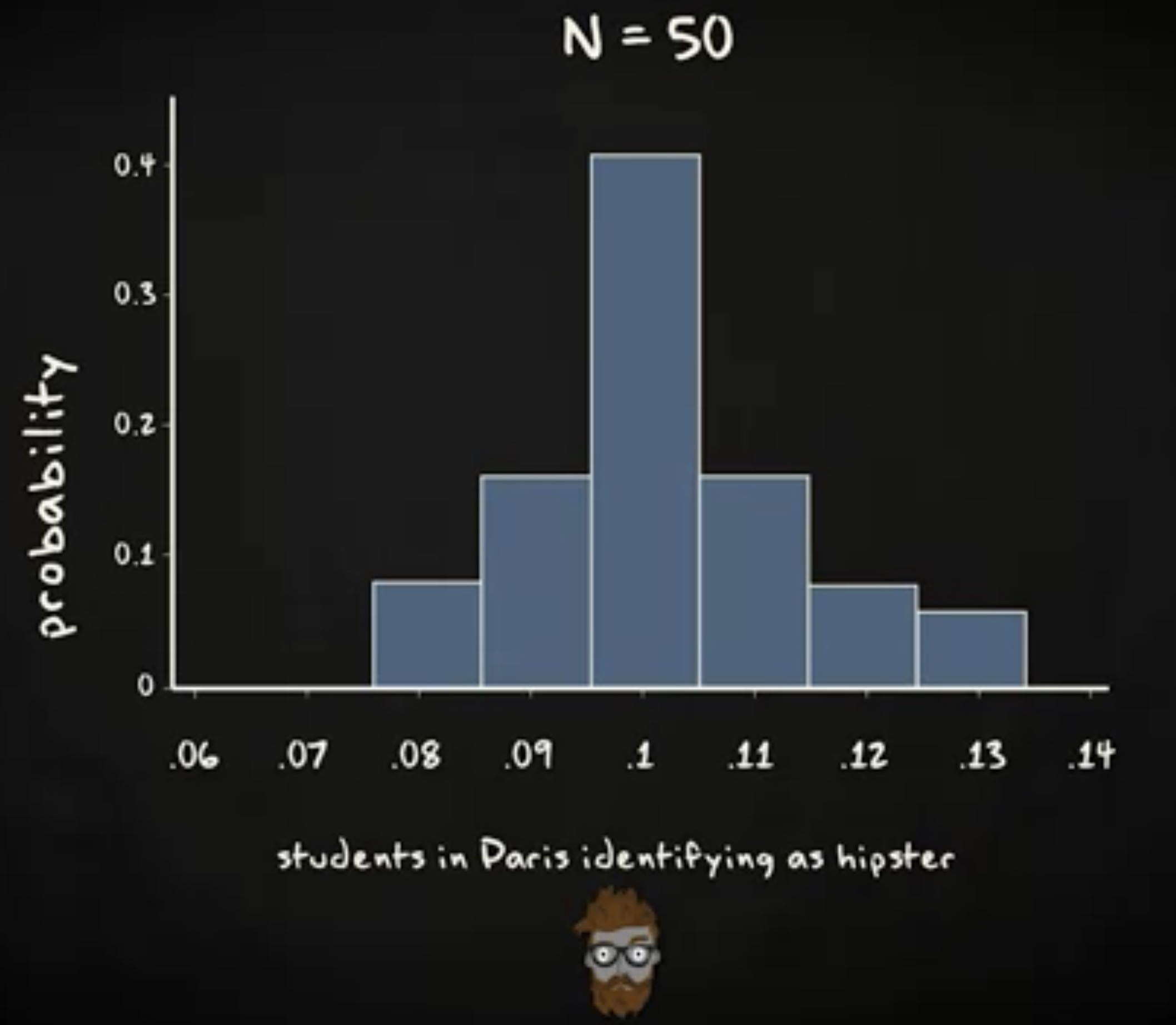
假定我的 100 的受试者里有 17% 报告他们的宝宝喜欢在换尿布时排便, 83% 的受试者报告他们的宝宝不会这样做。我们由此得到一个 0.17 的比例,这个比例的新生儿父母的宝宝喜欢在换尿布时排便。当我们为比例构建置信区间时,我们引入样本比例的抽样分布。我们知道,只要样本足够大,这个抽样分布就是正态分布,并且均值等于总体比例 $\pi$ ,标准差 $\sigmap$ 等于 $ \sqrt {\frac {\pi (1-\pi)}{n}} $ 。我们还知道,找到一个比例处于均值两个标准差范围内的样本的概率,同时也是总体的比例,是 0.95 。 更精确的说,如果我们对应概率的 z 分数,我们会得到 1.96 。这意味着我们有 95% 的机会确定我们的样本比例会落在总体比例 1.96 个标准差范围内,这被我们称为 _误差界限 (margin of error) 。我们用于计算 95% 置信区间的公式如下:
其中 1.96 是对应 95% 置信区间的 z 分数。所以上面的公式我们也可以写成:
我们这里讨论的是 95% 的置信区间,意味着如果我们能从总体抽取无限多的样本,那么 95% 的情况下,我们的置信区间会包含总体比例 $\pi$ 。不过,你可能注意到,我们并不知道总体比例 $\pi$ 的值,所以就无从计算样本比例的抽样分布的标准差。因此,我们用一个估计值来代替总体参数 $\pi$ ,这个估计值来自样本统计量, $P$ ,由此得到下面的公式:
就像我们为均值构建置信区间时一样,我们称这个估计的标准差为 标准误差 (standard error) ,又称为标准误。 作为与均值的置信区间的对比,在构建比例的置信区间时,我们并不使用 t 分布。不过,你的数据需要满足一个必要的假定。你必须要有至少 15 个成功和 15 个失败。换言之, $np \geq 15$ 并且 $n (1-p) \geq 15$ 。如果不满足,那 你就不能基于上面的公式计算置信区间。现在回到例子,我们有 0.17 的比例报告宝宝在换尿布时排便。公式如下:
让我们先计算标准误差。0.17 乘以 0.83 ,除以 100 ,然后取平方根,结果是 0.038 。误差界限等于 1.96 乘以 0.038 ,约定于 0.07 。 0.17 减去 0.07 等于 0.10 ,0.17 加上 0.07 等于 0.24 。因此我们的置信区间是 0.10 到 0.24 。这意味着我们有 95% 的信心说,总体比例落在 0.10 到 0.24 之间。或者说,如果我们能抽取无限多容量为 100 的样本,那么对于每个样本我们计算这个误差界限下的置信区间,有 95% 的情况这个区间会包含总体的比例。这个 95% 置信区间说明,大部分宝宝并不喜欢在换尿布时排便。但另一方面,如果他们确实在这个时候排便了,也并奇怪。我们有 95% 的信心说有 10% 到 24% 的宝宝确实会在换尿布时排便。
置信水平
95% 的置信区间,告诉我们对于我们的点估计有 95% 的可信度,这个点估计可以是均值或者比例。或者说,如果能够抽取无限多的样本,近似于我们当前的样本,对所有的样本基于相同的误差界限计算 95% 的置信区间。那么 95% 的情况下,总体的参数值回落在这个置信区间内。同时也意味着, 5% 的情况,这个方法会产生一个不包含实际总体参数的区间。
如果你希望减少错误推断的可能性,你可以诉诸更大的置信区间,比如说 99% 。这一节中,我将向你演示如何改变置信水平,以及这么做会带来什么结果。
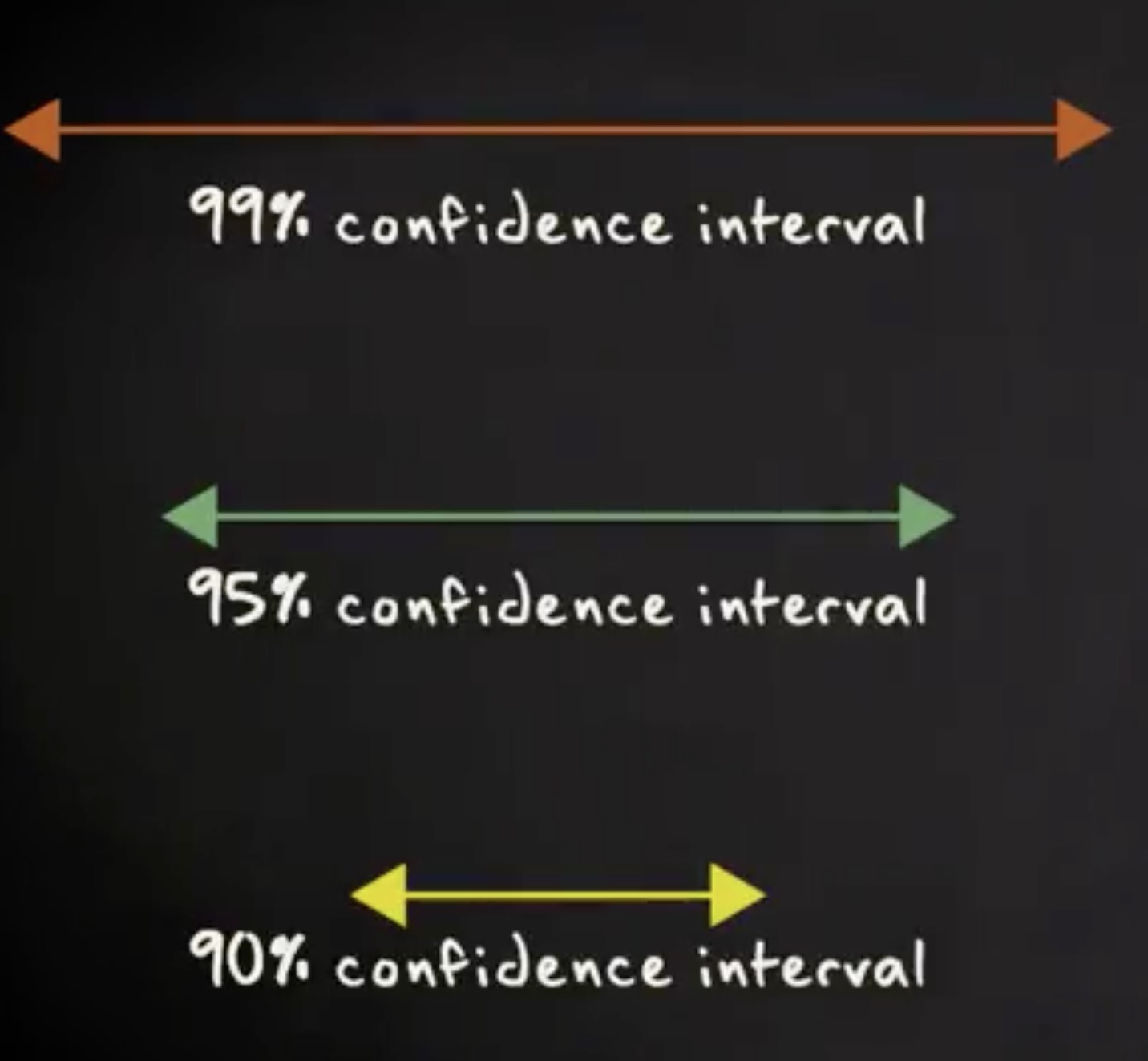
99% 置信区间和 95% 置信区间的唯一区别是不同的 z 分数,通过查询 z 表,代入公式,最终我们算得 99% 置信区间是 0.07 到 0.27 。对于 90% 的置信区间,结果是 0.11 到 0.23 。
我以图形演示,你会看到,更高的置信水平导致更宽的置信区间。换言之,我们想获得可信度越高的推断,那么就要接受更宽的误差界限。因此,我们需要在可信度和精度之间折中。在多数情况下,我们采用 95% 置信区间。
这个原理同样适用于均值的置信区间,区别在于在比例中,我们查询相关的 z 分数而在均值的案例中,我们查询相关的 t 分数,并且均值的计算中还要用到自由度,即 n 减去 1 。