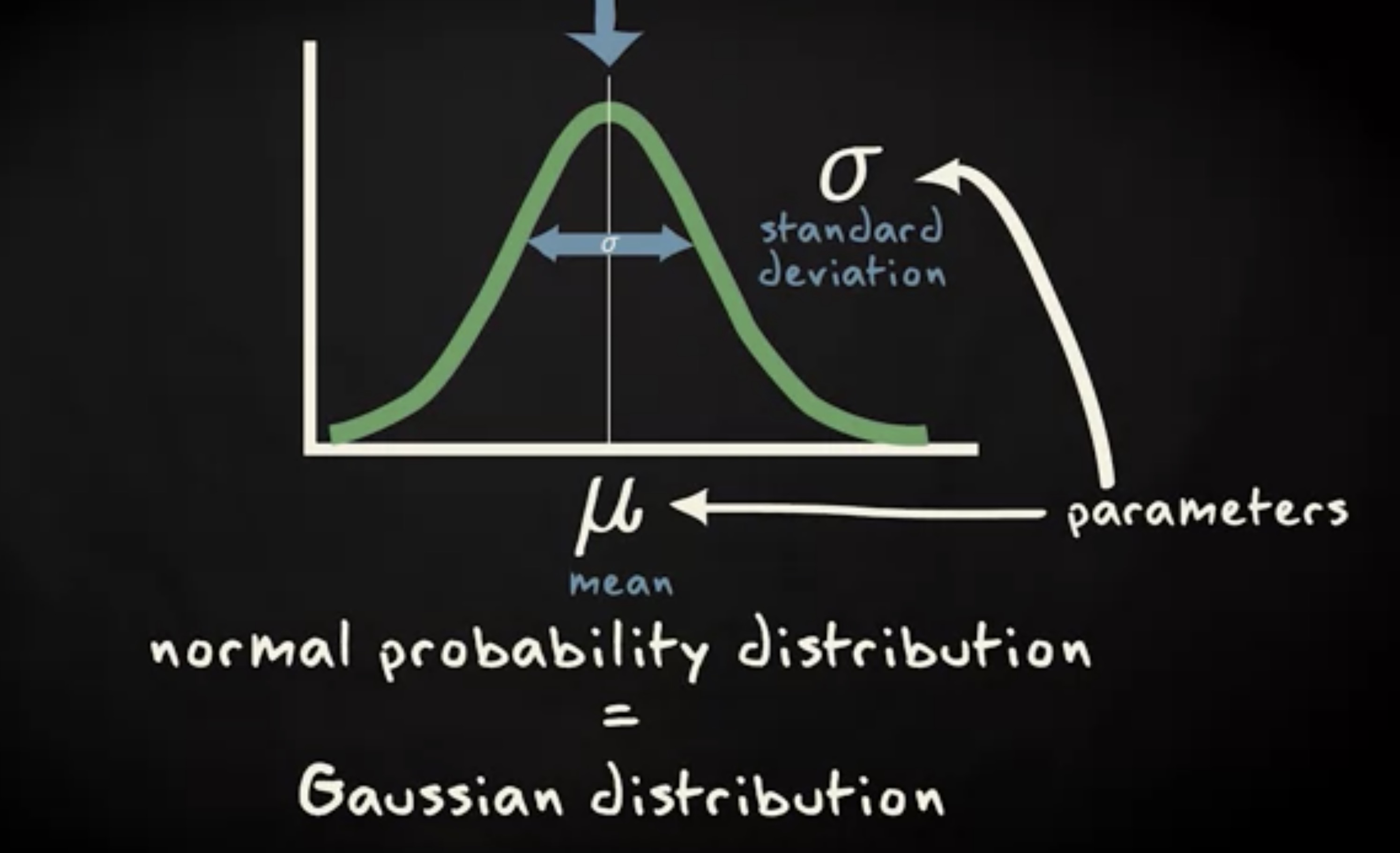
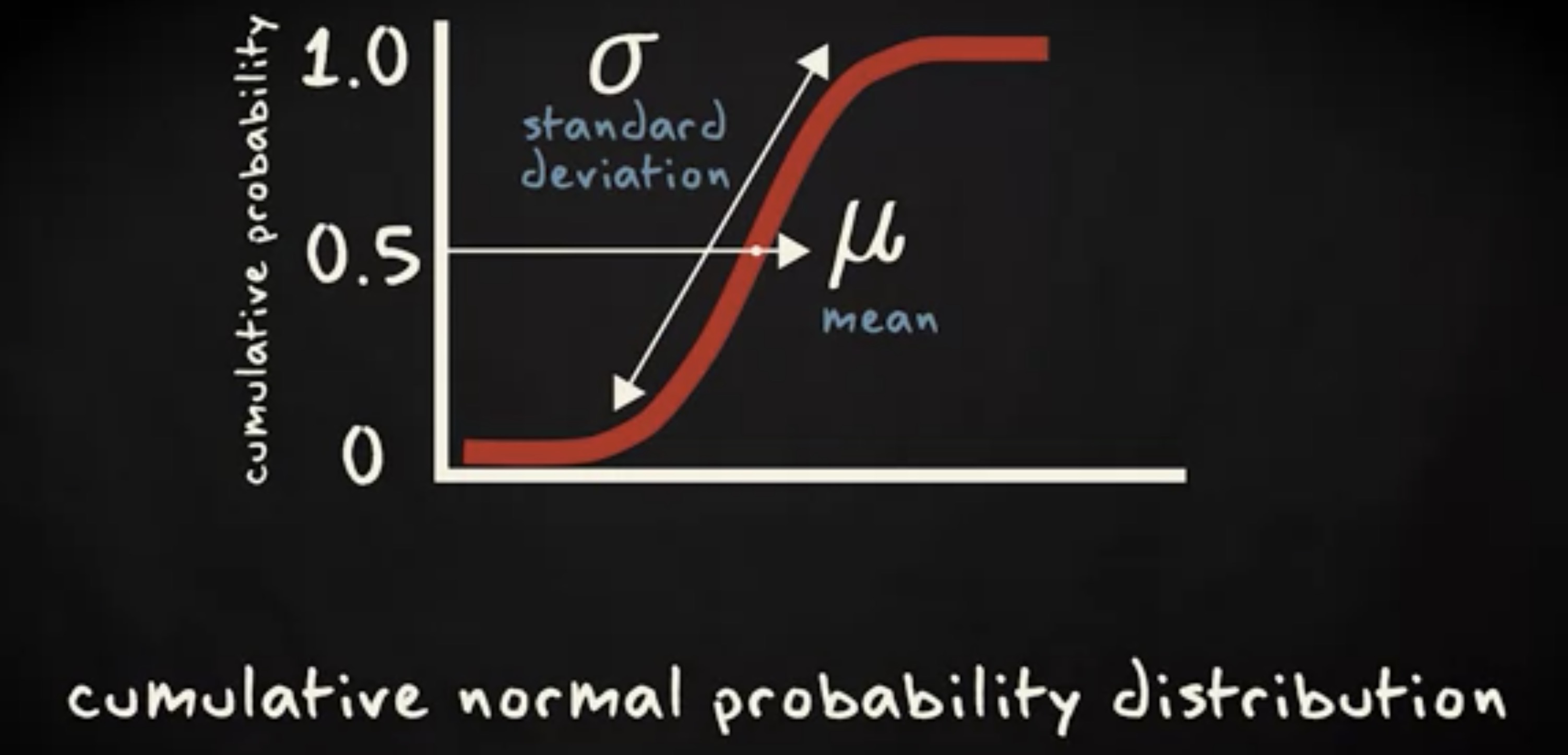
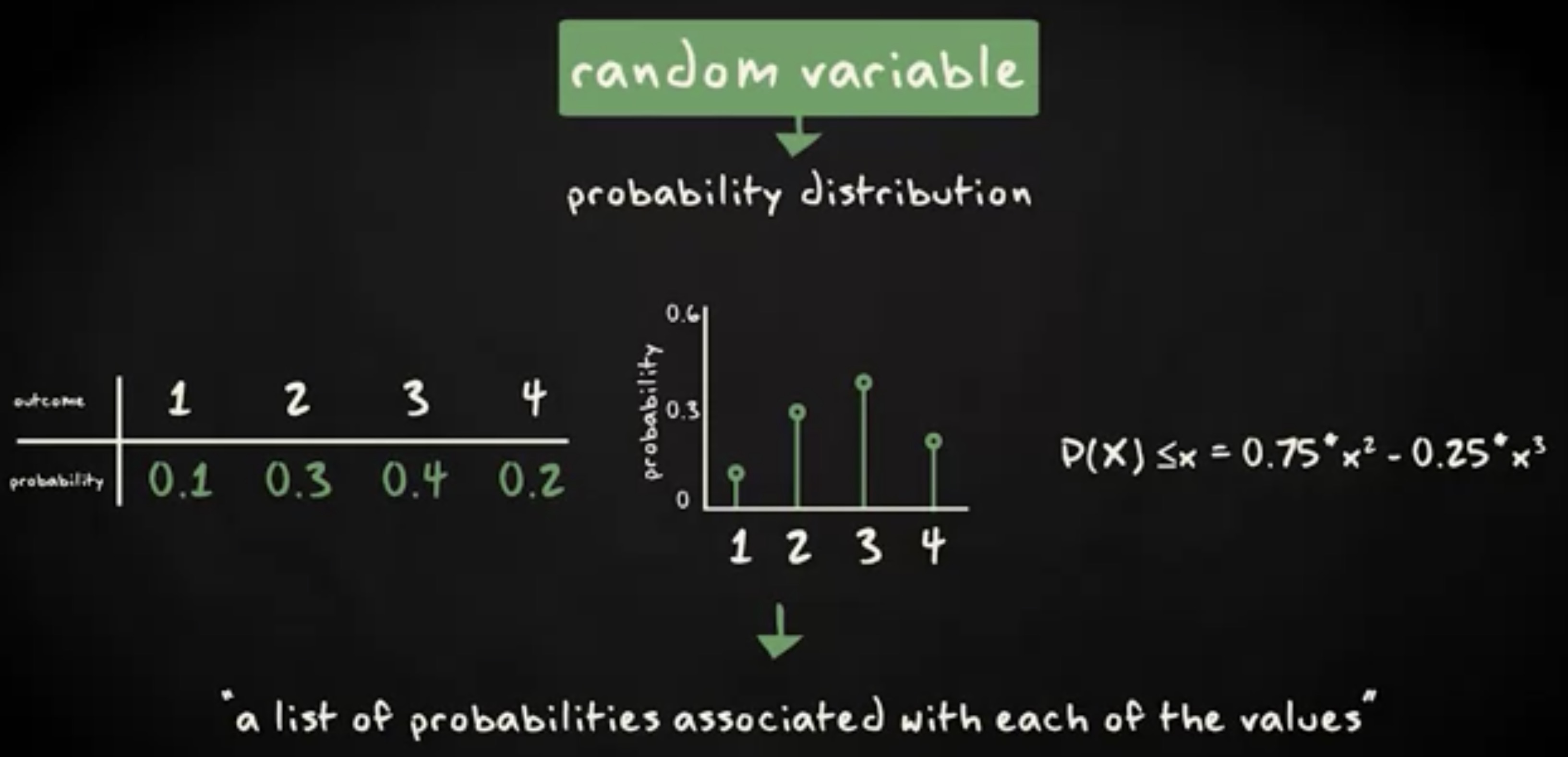
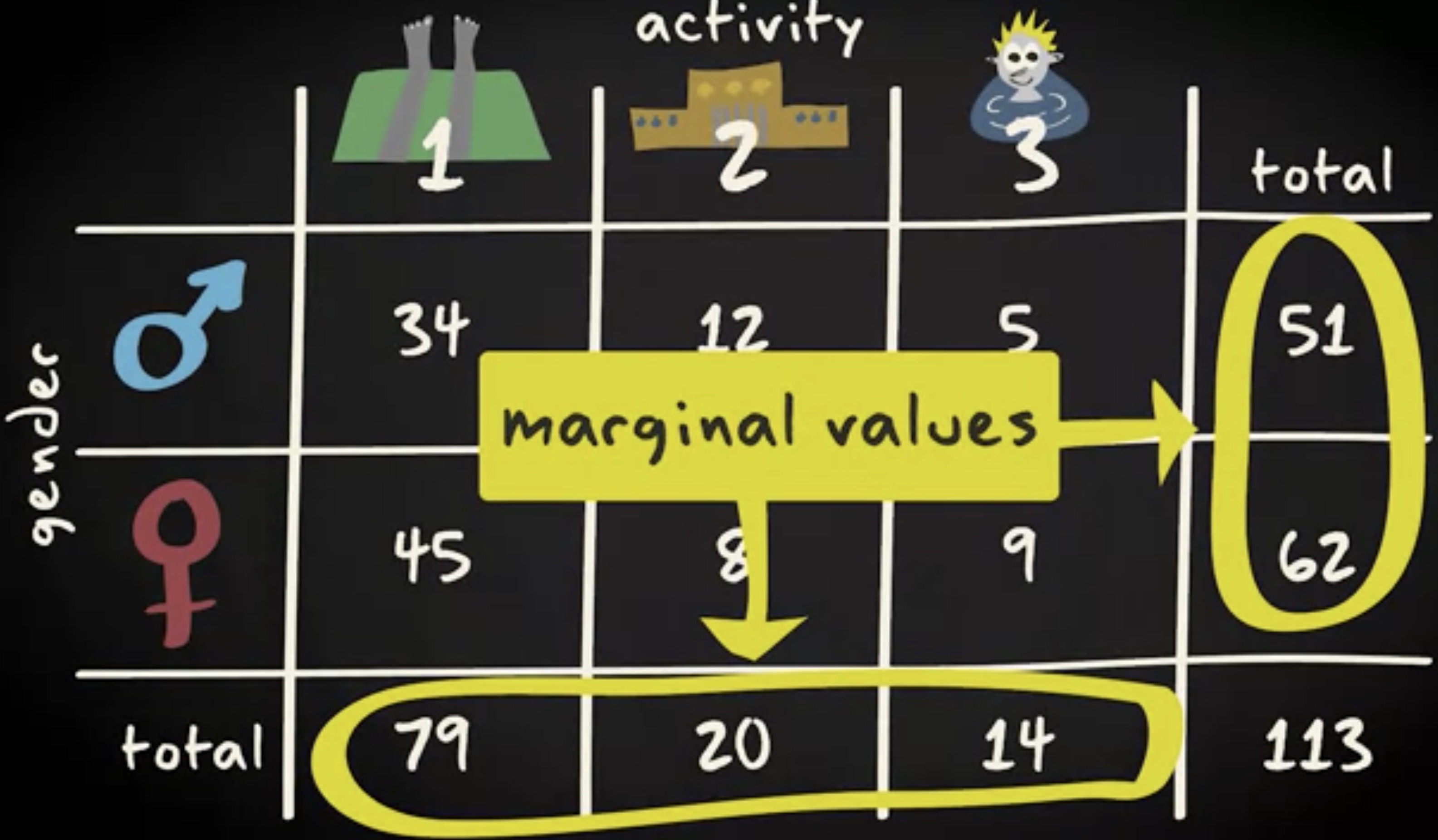
欢迎关注微信公众号「Swift 花园」
对于离散随机变量,有一个最重要的概率分布,它是 二项分布 (binomial distribution) 。二项分布处于二元数据。因为二元数据的情况非常多,所以二项分布使用频繁。
让我们从例子开始,你会在这些例子中看到两种结果。比如,参加会议是否迟到,投票赞成或者反对,噪音等级超过 80 分贝或者没有。当你收集这类现象的试验时,成功或者失败的数字服从二项分布。例如,你可以考虑每 25 个与会人员,有多少个迟到,或者投反对票的人有几个。
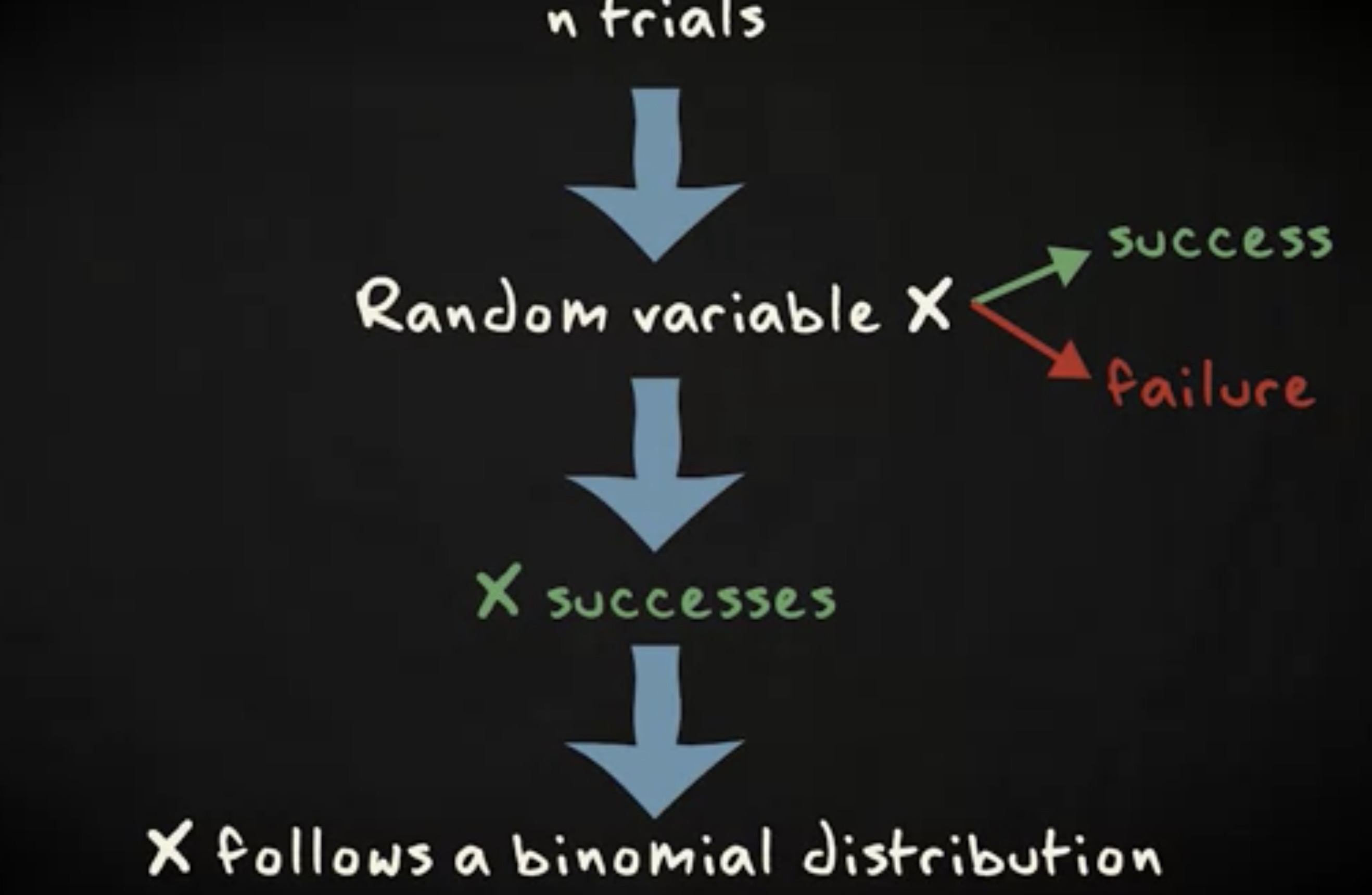
下面是你可以确定一个随机变量服从二项分布的条件:首先,每一个试验成功的概率相同;其次,试验在统计上是独立的 —— 即一个试验的结果不会影响其他试验。

实际上,你发现二项分布的三个要素。首先,试验现象有两种结果,并且成功概率是常量。这种实验被称为 伯努利试验验 (Bernoulli trial) 。其次,你观察试验结果 n 次。第三,你对成功的结果计数,记为 x 。这三个元素被结合成一个公式,它给出了在 n 次试验中取得特定数量成功结果的概率。公式如下:
你可以直接把 n,x 和 p 填进公式从而获得答案。

如公式所示,随机变量 x 只能取 0 到 n 的值。这很合理,因为你只能有有限次成功,0 ,1 , 2 ,直到 n 。因此这个公式是一个概率质量函数,它直接给出了匹配每个可能的 x 的概率值,你不必像考虑概率密度函数那样考虑区间。

感叹号不常见,它表示 阶乘法 (factorial) ,即把所有从 1 到指定的整数全部相乘的结果。例如, 4 阶乘等于 1 乘以 2 乘以 3 乘以 4 。 公式前部的这个阶乘的除法实际上是给出了无视顺序,从 n 个元素中选出 x 个元素的方法,它也被称为 二项系数 ( binomial coefficient) ,有的时候也速记为 $ C^x_n $ 。
现在,让我们把二项公式应用到特定的例子里吧。想象你每天通勤的路线上需要经过一座吊桥。这桥有 10% 的时间是打开的,但打开时机是随机的。那么你在一周中碰到 0 , 1, 2 ,直到 5 天的概率是多少呢?

实验有 5 次试验,遇到打开的桥的概率是 0.1 。因此,这里的二项分布的概率如下:
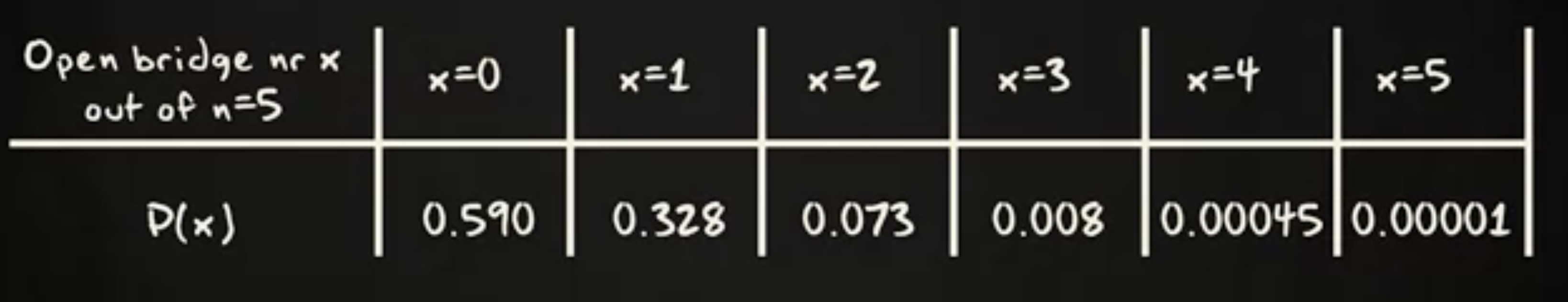
如果你把 6 个概率和 x 相乘并加总,你会发现这个值等于 1 。本应如此。