欢迎关注微信公众号「Swift 花园」
集合基础 —— 理论概念
在这篇教程中,我将介绍一些重要概念,它们是关于 集合 (set) ,即项的数据集。这对于理解概念以及得出概率的计算规则十分有用。同时,集合的特殊性还在于它不仅可用于概率演算,还用在逻辑学中。
让我们开始吧。如之前的教程中提到的,样本空间是随机现象所有结果的数据集。举个例子,抛一枚硬币两次,有四种可能的结果。事件是样本空间的子集。例如,最后一次抛硬币你得到正面朝上。
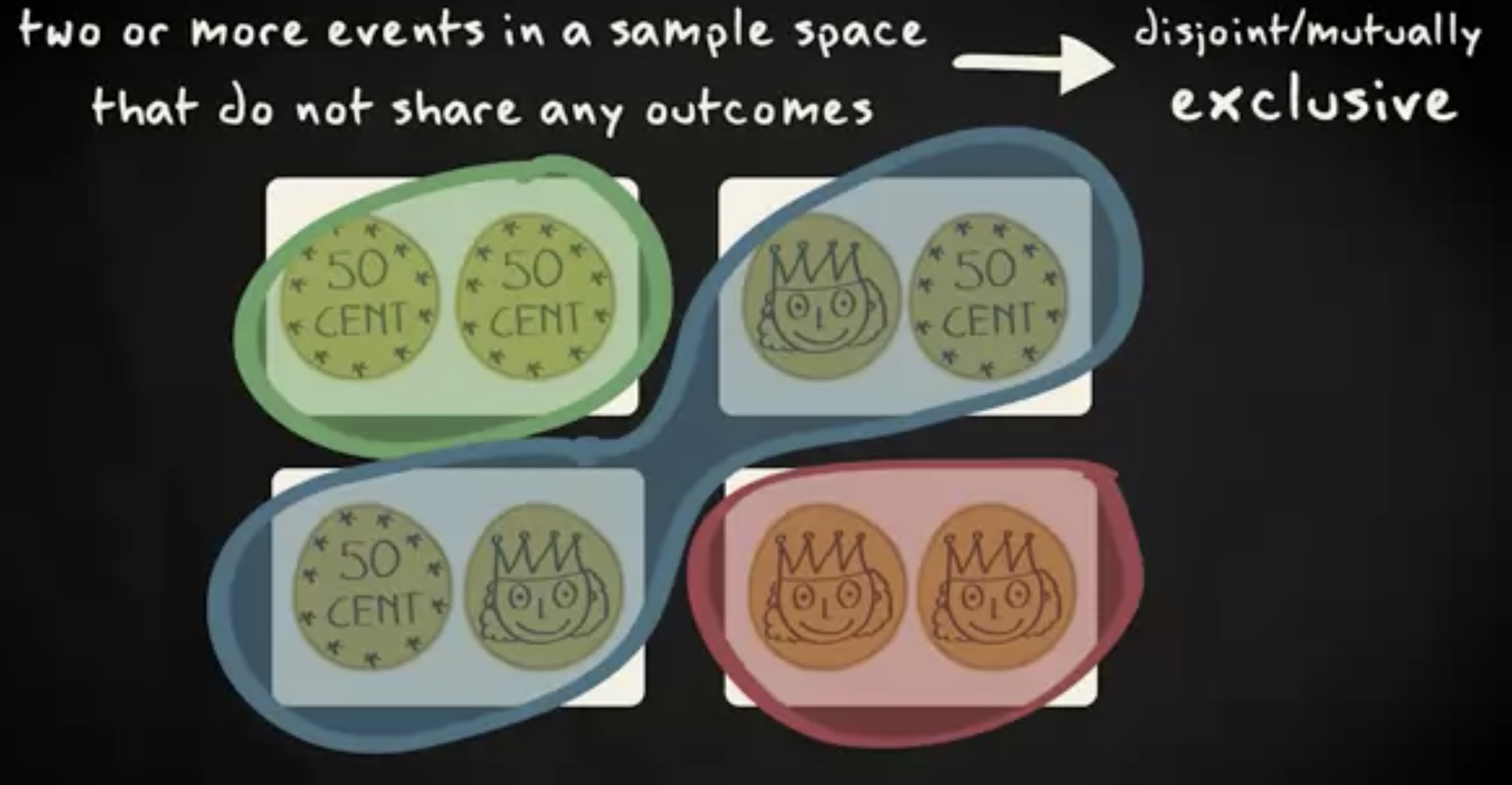
我们看到,一个样本空间可以两个或更多结果完全不同的事件。比如,抛硬币两次,0 次正面朝上,1 次正面朝上, 2 次正面朝上。它们被称为 互斥 (disjoint) 的事件。另外一个术语叫 互不相容 (mutually exclusive) 。
有一对特殊的互斥事件,某个事件和它的对立面 (即这个事件不发生的事件)。这种上下文中,对立的事件被称为 补集 (complement) 。比如,这里可以是没有正面朝上和其他三种情况互为补集。

你也可以有多个事件共同填满完整的样本空间。这些事件被称为 完全穷尽 (collectively exhaustive) 事件。如果它们彼此不重叠,就是 相互独立,完全穷尽 (disjoint collectively exhaustive) 。互斥事件相关联的概率之和小于或者等于 1 ,完全穷尽事件的概率之和等于 1 。

直觉上很容易理解这些概念,它们可以通过 文氏图 (Venn diagrams) 来表达。文氏图通过简单的几何形状来呈现集合或者集合的部分。